해시 테이블은 키(key)를 값(value)에 매핑할 수 있는 구조인, 연관 배열 추상 자료형을 구현하는 자료구조다.
key에 해시함수를 적용하여 계산한 값을 색인(index)으로 삼아 데이터를 저장한다.
create, read, update, delete 연산이 가능하다.
충돌의 문제가 없다면 1:1 매핑 구조를 띠므로 시간복잡도는 O(1)O(1)이다.
1.2 버킷(bucket)과 슬롯(slot)
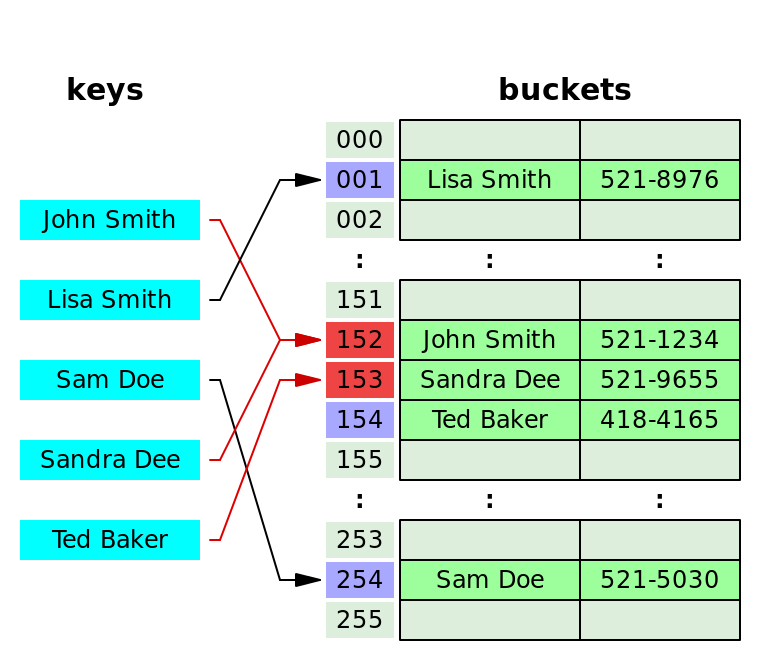
해시 테이블에서 값은 버킷(bucket)과 슬롯(slot)으로 이루어진 형태의 테이블에 저장된다.
(이 테이블 자체를 버킷이라고 표현 하기도 함)
버킷(bucket) : 여러개의 슬롯을 저장하는 레코드 형태의 자료 구조로, 버킷의 갯수는 고정적이다.
슬롯(slot) : 해시와 매핑되는 값이 저장되어 있는 공간으로, 하나의 버킷 안에는 여러개의 슬롯이 존재할 수 있다. 슬롯은 하나 이상의 값을 저장할 수 있다.
2. 해시함수
해시테이블에서 중요한 것은 키마다 고유한 인덱스를 설정하는 것이다. 이때 해시함수가 중요한 역할을 한다.
해시함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑해주는 함수인데 임의의 데이터마다 고유한 결과값을 계산한다.(이러한 해시함수의 특성을 이용하므로 1대1 매핑이 가능해진다.)
이때 서로 다른 입력값의 해시함수 결과값이 같을 경우 충돌(Collision)이 발생했다고 한다.
좋은 해시함수는 아래와 같은 조건을 가진다.
해시함수 값 충돌의 최소화
쉽고 빠른 연산
해시테이블에 값이 고르게 분포
사용할 키의 모든 정보를 사용
해시테이블 사용 효율이 높을 것
3. 충돌과 해결 방안
해시 테이블 개념 자체는 이해하기 어렵지 않다. 충돌이 발생할 때 어떻게 해결하느냐가 중요한 문제가 된다.
아무리 우수한 해시함수라도 충돌은 필연적으로 일어난다. 충돌을 설명할 때 드는 가장 흔한 예시가 '생일 문제'이다. 모인 사람 중 생일이 같은 사람이 2명 이상 있을 확률이 23명이 모이면 50%를 넘고, 57명이 모이면 99%를 넘는다. 이처럼 충돌은 생각보다 흔한 일이다.
또한 해시테이블이 가장 이상적으로 구성될 경우 탐색, 삽입, 수정, 삭제가 모두 O(1)에 가능하지만 충돌이 발생하여 만약 모든 데이터가 같은 버킷에 저장되었다고 한다면 최악의 경우 O(n)이 소요된다. 이와 같이 충돌은 해시테이블의 성능을 좌우하는 중요한 요소이다.
적재율(load factor)
해시함수를 다시 작성할지, 해시테이블의 크기를 조정해야 할지 결정할 때 적재율이라는 개념을 사용한다.
적재율은 다음과 같이 산출된다.
loadfactor=nk
여기서 n는 해시테이블에 저장된 데이터 개수, k는 버킷의 개수이다.
이 적재율은 해시함수가 키들을 잘 분산했는지 말하는 효율성 측정에도 사용된다.
적재율이 1이 넘으면 반드시 충돌이 발생한다.
개별 체이닝(seperate chaining)
충돌이 일어나면 연결리스트로 연결하는 방식이다.
John Smith와 Sandra Dee가 충돌이 발생했다. 이때 John smith를 저장하고, 그에 Sandra Dee를 연결리스트로 연결한다.
특정위치가 선점되어 있으면 바로 그 다음 위치를 확인하는 식이다. 구현이 간단하고 전체적 성능이 좋은 편이다.
그러나 데이터가 고르게 분포되지 않아 전체적으로 해싱 효율을 떨어트릴 수 있다.
로드팩터를 넘어서게 되면 그로스 팩터의 비율에 따라 더 큰 크기의 버킷을 생성한 후 새롭게 복사하는 리해싱 작업이 일어난다.
언어별 해시테이블 구현
개별체이닝은 체이닝 시 malloc으로 메모리를 할당하여야 하므로 오버헤드가 높아지는 단점이 있다.
오픈 어드레싱은 그에 비해 일반적으로 체이닝에 비해 성능이 더 좋으나 슬롯이 80퍼센트 이상 차게 되면 성능 저하가 일어나고, 로드팩터 1이상은 저장할 수 없다. 최근 루비나 파이썬 같은 언어들은 오픈 어드레싱 방식을 택해 성능을 높이고, 로드 팩터를 작게 잡아 성능 저하 문제를 해결한다.
음의 가중치가 없는 그래프의 한 정점에서 다른 정점까지의 최단 경로(거리)를 구하는 알고리즘이다.
음의 가중치가 있을 때는 벨만-포드 알고리즘을 사용할 수 있다.
가능한 모든 노드쌍의 최단 거리를 구할 때는 플로이드-워셜 알고리즘을 사용한다.
BFS를 기본으로 한다.
2. 다익스트라 알고리즘 동작 방식
출발 노드로부터 각 노드까지 최단 경로를 저장할 배열 distance[v]를 초기화하고, 출발 노드의 인덱스에는 0, 다른 노드에는 매우 큰 값을 저장한다(무한에 근접하도록 distance의 원소 타입의 최댓값으로 설정하면 된다).
현재 노드를 뜻하는 노드 A에 출발 노드 번호를 저장한다.
A로부터 갈 수 있는 임의의 노드 B에 대해, A까지 최단거리(distance[A]) + A에서 B까지의 거리(graph[A][B])와 기존에 계산한 B까지의 최단거리(distance[B])를 비교한다. (min(distance[A]+graph[A][B], distance[B])) INF와 비교할 경우 무조건 전자가 작다.
만약 전자가 더 작다면, 즉 더 짧은 경로일 경우 distance[B]를 갱신한다.
A의 모든 인접 노드에 대해 이 작업을 수행한다.
모든 인접 노드에 대해 위 작업을 마쳤으면, A를 '방문 완료'로 처리하여 중복 탐색을 방지한다.
'미방문' 상태인 모든 노드들 중, 출발점으로부터 거리가 가장 짧은 노드를 하나 골라서 그 노드를 A에 저장한다.
도착 노드가 '방문 완료' 상태가 되거나, 혹은 더 이상 미방문 상태의 노드를 선택할 수 없을 때까지, 3~7을 반복한다.
이 작업을 마친 뒤, 도착 노드에 저장된 값(distance[end])이 바로 A로부터의 최단 거리이다. 만약 이 값이 INF라면, 중간에 길이 끊긴 것임을 의미한다.
3. 구현(파이썬)
3.1 단순한 방식
defdijkstra(start, n):
infos = [[1, 2, 2], [1, 3, 1], [2, 4, 1], [2, 5, 2], [3, 4, 3], [4, 5, 1], [5, 6, 1]]
INF = 10e9
distance = [INF] * (n + 1)
graph = [[] for i inrange(n + 1)]
visited = [False] * (n + 1)
for v, w, u in infos:
graph[v].append((w, u))
for v, w in graph[start]:
distance[v] = w
defget_smallest_node():
smallest_value = INF
index = 1for i inrange(1, n+1):
if distance[i] < smallest_value andnot visited[i]:
smallest_value = distance[i]
index = 0return index
for _ inrange(n-1):
now = get_smallest_node()
visited[now] = Truefor child in graph[now]:
c_node = child[0]
cost = distance[now] + child[1]
if cost < distance[c_node]:
distance[c_node] = cost
이 경우 시간복잡도는 O(v2)이다.
3.2 우선순위큐 이용
from collections import defaultdict
import heapq
infos = [[1, 2, 2], [1, 3, 1], [2, 4, 1], [2, 5, 2], [3, 4, 3], [4, 5, 1], [5, 6, 1]]
INF = 10e9
distance = defaultdict(int)
graph = defaultdict(list)
Q = []
for u, v, w in infos:
graph[u].append([v, w])
Q.append((0, start))
while Q:
current_cost, current_node = heapq.heappop(Q)
if distance[current_node] < current_cost:
continuefor child in graph[current_node]:
child_node = child[0]
child_cost = child[1]
alt_cost = current_cost + child_cost
if alt_cost < distance[child_node]:
heapq.heappush(Q, (alt_cost, child_node))
print(distance)
※ 우선순위 큐를 활용한 다익스트라 알고리즘의 시간복잡도
우선순위 큐를 사용할 경우 위 동작방식 7번에서 시간복잡도를 크게 줄일 수 있다.
우선순위 큐를 사용하면 한번 처리된 노드는 더이상 처리되지 않는다. 즉 노드를 하나씩 꺼내 검사하는 반복문(while문)은 노드의 개수 V 이상의 횟수로는 반복되지 않는다. 또한 V번 반복될 때마다 각각 자신과 연결된 간선들을 모두 확인한다. 따라서 현재 우선순위 큐에서 꺼낸 노드와 연결된 다른 노드들을 확인하는 총 횟수는 총 최대 간선의 개수 E만큼 연산이 수행될 수 있다. 일반적으로 힙연산의 시간복잡도는 O(logn)이고 O(logE)를 E개의 원소에 대하여 반복하는 것으로 볼 수 있으므로 시간복잡도는 O(ElogE)로 표현할 수 있다.
이때 중복 간선을 포함하지 않는 경우, E는 항상 V의 제곱보다 작다. 왜나하면, 모든 노드끼리 서로 다 연결되어 있다고 했을 때 간선의 개수를 약 V2으로 볼 수 있고 항상 E는 V2이하이기 때문이다.
O(ElogE) <= O(ElogV2)이고, O(ElogV2)는 O(2∗ElogV)이므로 O(ElogV)로 표현할 수 있다.
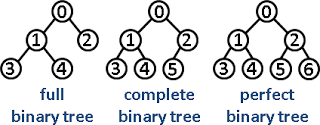
힙은 완전 이진트리를 기반으로 하는 자료구조로서, 여러 값 중에서 최댓값이나 최솟값을 빠르게 찾기 위하여 고안되었다.
우선순위 큐에 활용된다.
2. 힙의 특징
힙은 최소 힙과 최대 힙으로 나눠지며 각각 아래의 특성을 만족한다.
최소 힙(Min Heap)의 경우 부모가 자식보다 작거나 같다.
최대 힙(Max Heap)의 경우 부모가 자식보다 크거나 같다.
중복 값을 허용한다.
정렬된 구조가 아니다. 최소 힙의 경우 부모가 자식보다 작거나 같다는 조건만 만족할 뿐 정렬되어 있지 않다. 예를 들어 오른쪽 자식 노드가 레벨 차이에도 불구하고 왼쪽 노드보다 더 작은 경우도 있을 수 있다.
자식이 둘인 힙은 특별히 이진 힙이라고 부르고 자주 사용된다.
3. 힙의 구현
힙은 주로 배열로 구현한다.
직관적이고 쉽게 구현하기 위하여 인덱스 0은 사용하지 않고 1부터 사용한다.
부모 노드와 자식 노드의 관계
왼쪽 자식의 인덱스 = 부모의 인덱스 * 2
오른쪽 자식의 인덱스 = 부모의 인덱스 * 2 + 1
부모의 인덱스 = 자식의 인덱스 // 2
3.1 힙의 삽입
요소를 가장 하위레벨 최대한 왼쪽으로 삽입(배열로 표현할 경우 가장 마지막에 삽입)
부모값과 비교해 값이 더 작은 경우 위치 변경
계속해서 부모 값과 비교해 위치 변경
※ 시간복잡도는 O(logn)
3.2 힙의 추출(삭제)
루트를 추출한다.
추출 이후 아래의 과정으로 다시 힙의 특성을 유지한다.
추출 이후 비어 있는 루트에 가장 마지막 요소가 올라간다.
자식 노드와 값을 비교해서 자식보다 크다면 내려가는 과정을 반복한다.
※ 시간복잡도는 단순히 추출은 O(1)이나, 힙 유지에 O(logn) 소요
3.3 파이썬으로 이진 힙 구현
classBinaryHeap(object):def__init__(self):
self.items = [None] #don't use index 0 def__len__(self):returnlen(self.items) - 1# when, number k is inserted, swap when it is smaller than parentdef_percolate_up(self):
i = len(self)
parent = i // 2while parent > 0:
if self.items[i] < self.items[parent]:
self.items[parent], self.items[i] = self.items[i], self.items[parent]
i = parent
parent = i // 2# append number k and percolate_updefinsert(self, k):
self.items.append(k)
self._percolate_up()
# when extracting first item, move last item to first and swap with child when it is smaller than childdef_percolate_down(self, idx):
left = idx * 2
right = idx * 2 + 1
smallest = idx
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
if smallest != idx:
self.items[idx], self.items[smallest] = self.items[smallest], self.items[idx]
self._percolate_down(smallest)
defextract(self):
extracted = self.items[1]
self.items[1] = self.items[len(self)]
self.items.pop()
self._percolate_down(1)
return extracted