개요
이번 포스팅에서는 로지스틱 회귀에 대해 알아본다.
앞서 포스팅에서 소개했던 선형 회귀는 데이터의 구조를 선형으로 예측하는 모델이었으므로, 종속변수가 연속적인 값일 때 적용할 수 있는 모델이었다. 종속변수가 이산적일 때도 선형 회귀를 사용할 수 있을까?
아래의 사례를 살펴보자.

함수값 $\cfrac{1}{2}$ 기준으로 악성 여부를 판단하는 선형 모델이다. 현재의 데이터와 결과를 보면 잘 분류한 것으로 보인다.
그러나 다음의 그림을 보자.

데이터가 추가 되었고 데이터의 분포에 맞추어 모델이 수정되었다. 이때 함수값 $\cfrac{1}{2}$ 기준으로 분류하는 것은 적합하지 않아보인다. 이와 같이 새로운 데이터의 추가가 기존의 분류 모델에 큰 영향을 미치게 된다.
따라서 변량이 이산 데이터일 때 선형회귀 모델은 적합하지 않다. 이때 적용할 수 있는 모델이 바로 로지스틱 회귀 모델이다.
Logistic Regression
로지스틱 회귀 모델은 다음과 같은 구조를 띤다.

정의
로지스틱 회귀의 가설함수를 살펴보자. 시그모이드 함수라는 이름으로 잘 알려져 있다.
$$
h_\theta(x) = g(\theta^Tx)
$$
$$
z = \theta^Tx
$$
$$
g(z) = \cfrac{1}{1+e^{-z}}
$$
의미
$x$에 대하여 $f(x)$의 값이 $y$일 확률을 뜻한다.
다음이 성립한다.
$$h_\theta(x) = P(y=1|x;\theta) = 1 - P(y = 0 |x;\theta)$$
$$P(y = 0|x;\theta) + P(y = 1|x;\theta) = 1$$
※시그모이드 함수를 사용하는 이유
아래 블로그에 감동적일 정도로 매우매우 잘 설명되어 있다ㅠㅠ. 그래도 내 나름대로 다시 정리해보겠다.
(https://gentlej90.tistory.com/69)
Logistic Regression Part.1
많은 블로그들과 책들에서 로지스틱 회귀에 대해 잘 설명해 놓은것이 많다. 따라서 이 포스팅은 로지스틱 회귀방법에 대해 설명을 하겠지만 자세히 하진 않고 이 내용을 본인이 이해한 방식대
gentlej90.tistory.com
위에서 보았듯기존의 회귀식은 좌변과 우변이 모두 연속형인 수를 가정하고 있다.
그런데 로지스틱 회귀에서 좌변(y)는 이산값이다.
우변값은 $-\infty$~$\infty$인데 좌변이 이산값이므로 등호를 만족할 수가 없다.
이에 좌변의 범위를 맞춰주는 작업을 하게 된다. 이때 사용하는 것이 Logit(Log + Odds) 변환이다.
Logit 변환은 오즈에 로그를 씌운 것이다.
오즈비는 어떠한 일이 일어날 확률을 일어나지 않을 확률로 나눈 것을 말하고 공식은 다음과 같다.
$$\cfrac{p(y=1|x)}{1-p(y=1|x)}$$
p(y=1|x)가 1에 가까워질수록 무한대에 수렴하고, 0이면 0이 되므로 오즈비는 (0, $\infty$) 의 범위를 가진다.
아직 우변이 음수의 범위를 가질 수도 있기 때문에 한번의 변환을 더 거쳐야 하는데 그것이 로그변환이다.
$$log(\cfrac{p(y=1|x)}{1-p(y=1|x)})$$
이제 우변과 동등한 (-$\infty$, $\infty$)의 범위를 갖게 되었다.
이제 x와 w파라미터를 통해 일반 회귀식으로 logit값을 예측할 수 있게 되었다. 그러나 우리는 logit값이 아닌 p값, 즉 1이 될 확률을 알고 싶은 것이다. 따라서 p에 대하여 식을 다시 정리한다.
$$log(\cfrac{p(y=1|x)}{1-p(y=1|x)}) = w_0 + w^Tx $$
$$\cfrac{p(y=1|x)}{1-p(y=1|x)} = e^{w_0 + w^Tx }$$
$$p(y=1|x)=e^{w_0 + w^Tx }({1-p(y=1|x)})$$
$$p(y=1|x) = e^{w_0 + w^Tx }-e^{w_0 + w^Tx }{p(y=1|x)}$$
$$p(y=1|x) + e^{w_0 + w^Tx }{p(y=1|x)} = e^{w_0 + w^Tx }$$
$$p(y=1|x)(1 + e^{w_0 + w^Tx }) = e^{w_0 + w^Tx }$$
$$p(y=1|x) = \cfrac{e^{w_0 + w^Tx }}{(1 + e^{w_0 + w^Tx })}$$
$$\cfrac{e^{w_0 + w^Tx }}{1 + e^{w_0 + w^Tx }} = \cfrac{1}{1+e^{-(w_0 + w^Tx)}}$$
logistic function이 도출되었다. 이제 회귀식의 값을 input으로 받아 0~1의 확률값을 반환하는 이 함수를 통해 확률을 구할 수 있게 되었다. 확률을 우리가 세운 기준점(cutoff값)과 비교하면 분류가 끝이 난다.
Logistic Regression의 비용함수
로지스틱 회귀의 비용함수는 선형회귀의 비용함수와 다른 함수를 사용한다.
선형회귀의 비용함수는 다음과 같았다.
$$J(\theta) = \cfrac{1}{m}\sum_{i=1}^m\cfrac{1}{2}(h_\theta(x^{(i)}) - y^{(i)})^2 $$
로지스틱 회귀의 가설함수는 비선형함수이기 때문에 이를 그대로 적용하면 $J(\theta)$가 볼록하지 않은(Non-Convex) 함수가 된다.

정의
로지스틱 회귀의 비용함수는 다음과 같다.
$$Cost(h_\theta(x), y) = -log(h_\theta(x)) if y=1$$
$$Cost(h_\theta(x), y) = -log(1-h_\theta(x)) if y=0$$
이 Cost함수는 크게 두 가지 특징을 가진다.
- $y=1$일 때, $h_\theta(x)$가 1에 가까워질수록(가설이 정확할수록) cost가 0에 수렴하고, $h_\theta(x)$가 0에 가까워질수록 cost가 무한대로 수렴하는 특징을 가진다. $y=0$일 때는 반대로 $h_\theta(x)$가 0에 가까워질수록 cost가 0에 수렴하고, $h_\theta(x)$가 1에 가까워질수록 cost가 무한대로 수렴하는 특징을 가진다.
- Cost함수가 선형이므로 비용함수 $J(\theta)도 볼록(Convex)한 함수임을 만족한다.

비용함수의 일반화
$$Cost(h_\theta(x), y) = -ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))$$
$$J(\theta) = -\cfrac{1}{m}\sum_{i=1}^m[-y^{(i)}log(h_\theta(x^{(i)})) -(1-y^{(i)})log(1-h_\theta(x^{(i)}))]$$
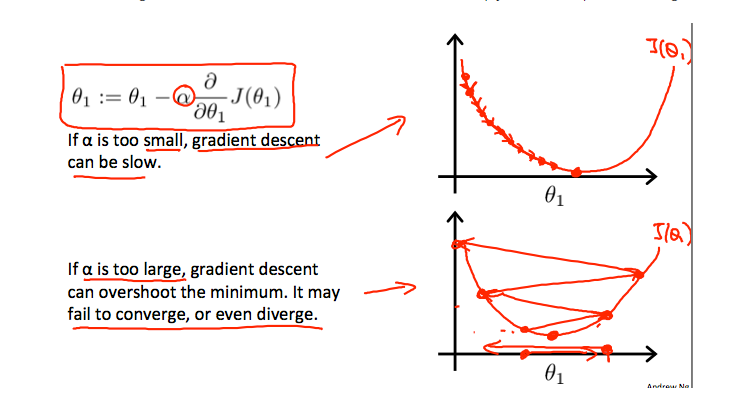
Logistic Regression에서 Gradient Descent
Gradient Descent는 아래의 식을 반복적으로 계산하여 수행한다.
$$\theta_j := \theta_j - \alpha\cfrac{\partial}{\partial\theta} J(\theta)$$
위에서 구한 $J(\theta)를 대입하면 다음의 식이 도출된다.
$$\theta_j := \theta_j - \cfrac{\alpha}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)}$$
그런데 최종적인 형태는 선형 회귀의 Gradient Descent와 거의 같은 형태가 도출되었다.
차이점은 $h(x)$가 $\theta^TX$가 아닌 $ \cfrac{1}{1+e^{-\theta^Tx}}$ 라는 것이다.
'Information Technology > Machine Learning' 카테고리의 다른 글
| 다중 선형 회귀(Multiple Linear Regression) (0) | 2021.01.25 |
|---|---|
| 경사 하강법(Gradient Descent) (0) | 2021.01.24 |
| 모델과 비용함수(Model and Cost Function) (0) | 2021.01.24 |
| 지도학습과 비지도학습 (0) | 2021.01.24 |