1. 해시 테이블(Hash Table)이란
1.1 정의 및 특징
해시 테이블은 키(key)를 값(value)에 매핑할 수 있는 구조인, 연관 배열 추상 자료형을 구현하는 자료구조다.
key에 해시함수를 적용하여 계산한 값을 색인(index)으로 삼아 데이터를 저장한다.
create, read, update, delete 연산이 가능하다.
충돌의 문제가 없다면 1:1 매핑 구조를 띠므로 시간복잡도는 \(O(1)\)이다.
1.2 버킷(bucket)과 슬롯(slot)
해시 테이블에서 값은 버킷(bucket)과 슬롯(slot)으로 이루어진 형태의 테이블에 저장된다.
(이 테이블 자체를 버킷이라고 표현 하기도 함)
- 버킷(bucket) : 여러개의 슬롯을 저장하는 레코드 형태의 자료 구조로, 버킷의 갯수는 고정적이다.
- 슬롯(slot) : 해시와 매핑되는 값이 저장되어 있는 공간으로, 하나의 버킷 안에는 여러개의 슬롯이 존재할 수 있다. 슬롯은 하나 이상의 값을 저장할 수 있다.
2. 해시함수
해시테이블에서 중요한 것은 키마다 고유한 인덱스를 설정하는 것이다. 이때 해시함수가 중요한 역할을 한다.
해시함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑해주는 함수인데 임의의 데이터마다 고유한 결과값을 계산한다.(이러한 해시함수의 특성을 이용하므로 1대1 매핑이 가능해진다.)
이때 서로 다른 입력값의 해시함수 결과값이 같을 경우 충돌(Collision)이 발생했다고 한다.
좋은 해시함수는 아래와 같은 조건을 가진다.
- 해시함수 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시테이블에 값이 고르게 분포
- 사용할 키의 모든 정보를 사용
- 해시테이블 사용 효율이 높을 것
3. 충돌과 해결 방안
해시 테이블 개념 자체는 이해하기 어렵지 않다. 충돌이 발생할 때 어떻게 해결하느냐가 중요한 문제가 된다.
아무리 우수한 해시함수라도 충돌은 필연적으로 일어난다. 충돌을 설명할 때 드는 가장 흔한 예시가 '생일 문제'이다. 모인 사람 중 생일이 같은 사람이 2명 이상 있을 확률이 23명이 모이면 50%를 넘고, 57명이 모이면 99%를 넘는다. 이처럼 충돌은 생각보다 흔한 일이다.
또한 해시테이블이 가장 이상적으로 구성될 경우 탐색, 삽입, 수정, 삭제가 모두 \(O(1)\)에 가능하지만 충돌이 발생하여 만약 모든 데이터가 같은 버킷에 저장되었다고 한다면 최악의 경우 \(O(n)\)이 소요된다. 이와 같이 충돌은 해시테이블의 성능을 좌우하는 중요한 요소이다.
적재율(load factor)
해시함수를 다시 작성할지, 해시테이블의 크기를 조정해야 할지 결정할 때 적재율이라는 개념을 사용한다.
적재율은 다음과 같이 산출된다.
\( load factor = \frac {n}{k} \)
여기서 n는 해시테이블에 저장된 데이터 개수, k는 버킷의 개수이다.
이 적재율은 해시함수가 키들을 잘 분산했는지 말하는 효율성 측정에도 사용된다.
적재율이 1이 넘으면 반드시 충돌이 발생한다.
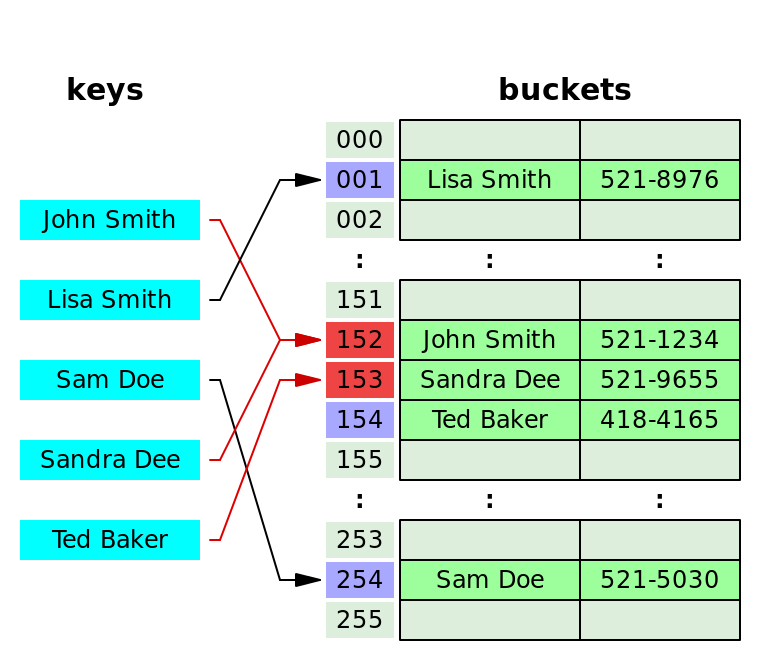
개별 체이닝(seperate chaining)
충돌이 일어나면 연결리스트로 연결하는 방식이다.

John Smith와 Sandra Dee가 충돌이 발생했다. 이때 John smith를 저장하고, 그에 Sandra Dee를 연결리스트로 연결한다.
1. 키의 해시 값을 계산한다.
2. 해시값을 이용해 배열의 인덱스를 구한다.
3. 같은 인덱스가 있다면 연결리스트로 연결한다.
잘 구현한 경우 \(O(1)\)이지만 최악의 경우 \(O(n)\)이다.
오픈 어드레싱(open addressing)
충돌이 발생하면 탐사(probing)을 통해 빈 공간을 찾아 저장하는 방식이다.
모든 값이 해시값과 일치하는 공간에 저장되지 않을 수 있는 것이다.
오픈어드레싱의 한 가지 방식 중 선형 탐사가 있다.
충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 하나씩 진행한다.
특정위치가 선점되어 있으면 바로 그 다음 위치를 확인하는 식이다. 구현이 간단하고 전체적 성능이 좋은 편이다.
그러나 데이터가 고르게 분포되지 않아 전체적으로 해싱 효율을 떨어트릴 수 있다.
로드팩터를 넘어서게 되면 그로스 팩터의 비율에 따라 더 큰 크기의 버킷을 생성한 후 새롭게 복사하는 리해싱 작업이 일어난다.
언어별 해시테이블 구현
개별체이닝은 체이닝 시 malloc으로 메모리를 할당하여야 하므로 오버헤드가 높아지는 단점이 있다.
오픈 어드레싱은 그에 비해 일반적으로 체이닝에 비해 성능이 더 좋으나 슬롯이 80퍼센트 이상 차게 되면 성능 저하가 일어나고, 로드팩터 1이상은 저장할 수 없다. 최근 루비나 파이썬 같은 언어들은 오픈 어드레싱 방식을 택해 성능을 높이고, 로드 팩터를 작게 잡아 성능 저하 문제를 해결한다.
| 언어 | 방식 |
| C++ | 개별체이닝 |
| 자바 | 개별체이닝 |
| 고 | 개별체이닝 |
| 루비 | 오픈어드레싱 |
| 파이썬 | 오픈어드레싱 |
'자료구조와 알고리즘 > 자료구조' 카테고리의 다른 글
| [자료구조] 연결 리스트(Linked List) (0) | 2022.04.04 |
|---|---|
| [자료구조] 힙(Heap) (0) | 2022.04.02 |
| [자료구조] 트리(Tree) (0) | 2022.04.02 |